2019高考报名人数达到了 1031 万的新高,作为一名三年前参考高考的准程序猿,赶在高考前,加班加点从零开始做了一款高考查分小程序,算是一名老学长送给学弟学妹们的高考礼。上线仅 1 个月,用户数就突破了 1k,关于小程序的介绍就不多说了,可以去搜【历年高考分数线查询】体验,今天主要谈谈技术原理和实现细节。
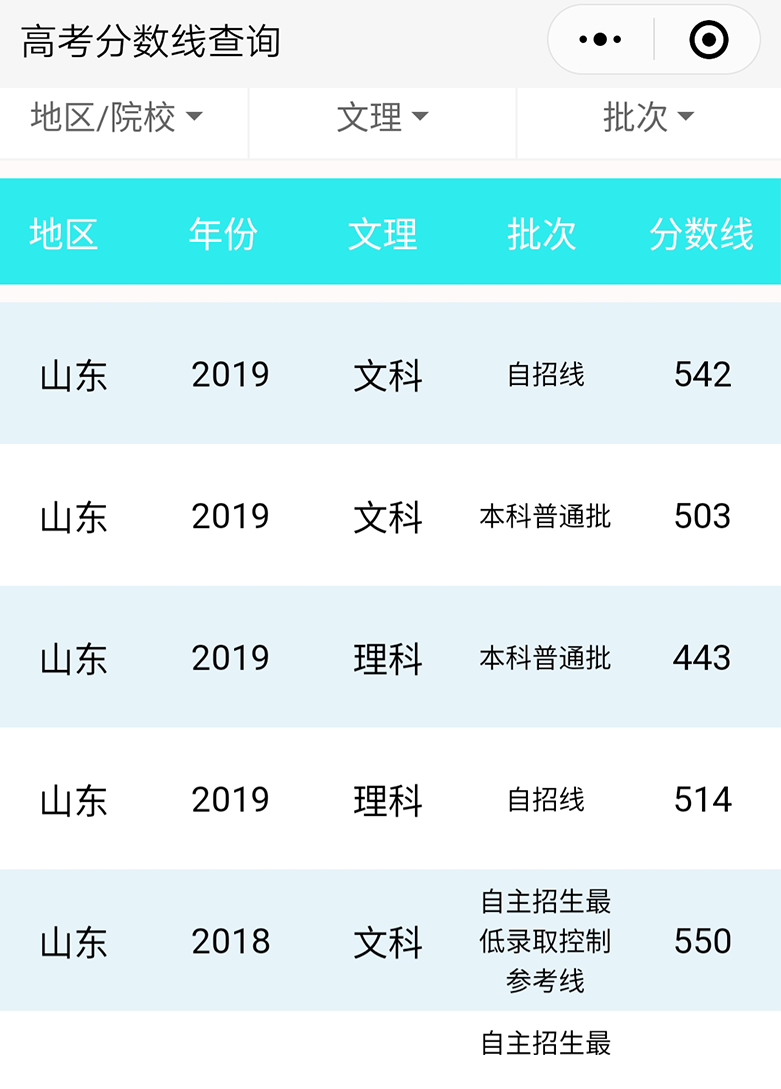
数据来源
小程序后台共收录近 30w 条数据,包含 2008-2017 年所有重点高校的各个批次的文理分科录取分数线以及 2008-2018 所有采用新课标一卷、新课标二卷、新课标三卷以及部分自主命题省份的从提前批到高职专科批的录取分数线,勉强称得上内容翔实。
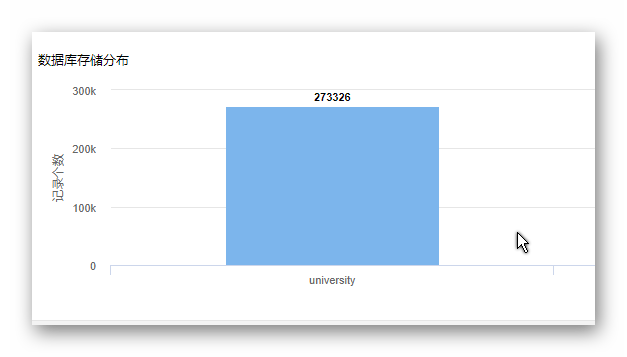
所有数据均采集自各大院校和各高考相关网站,由于数据量巨大,为提高速度,使用了 concurrent.futures (需要 Python3.5+) 模块里的 ThreadPoolExecutor 来构建线程池来并发执行多任务。
数据库采用的是 PgSQL,一款号称世界上最强大的开源数据库产品,所有数据均存在新建的 gaokao 数据库中,其下有两个表,university(院校的录取分)和 province(省份的批次线)
university 表说明
| 字段 | 解释 |
|---|---|
| name | 院校名称 |
| stu_loc | 生源地 |
| stu_wl | 文理科 |
| pc | 录取批次 |
| year | 年份 |
| score | 录取平均分 |
province 表说明
| 字段 | 解释 |
|---|---|
| year | 年份 |
| stu_loc | 考生所在地 |
| stu_wl | 文理科 |
| pc | 批次 |
| control | 本批次最低控制线 |
30w 的数据量,多个站点,并发爬取,数据冲突是不可避免地,在执行插入之前,首先过滤掉残缺不全的数据,比如在插入 university 表时某条数据缺少 pc 字段,那么这条记录就应该被舍弃,最严重的是数据重复,我采用的解决办法是:先查询待插入的数据是否已经存在, university 表的主码是(name,stu,stu_wl,pc,year),因为现实约束一个院校只能在一个年份在一个类别一个批次只能有一个录取平均分,如果不存在,才执行最后的插入,并 commit 提交事务。
后台搭建
在 30w 条数据拿到后,我打算后台采用 Flask+PgSQL 的模式实现,甚至在后台在阿里云服务器部署好,小程序端在开发者工具联调通过之后,小程序上线遇到到一个大麻烦,因为小程序要求线上运行不能通过 ip 地址访问后台,必须通过备案的域名访问,域名购买一个倒不麻烦,只是域名备案比较耗时间,需要一周多时间,而当时距离高考也就不到 5 天,在手足无措之时,无意间看到小程序云开发,关于小程序云开发,官网的介绍是:
开发者可以使用云开发开发微信小程序、小游戏,无需搭建服务器,即可使用云端能力。
云开发为开发者提供完整的原生云端支持和微信服务支持,弱化后端和运维概念,无需搭建服务器,使用平台提供的 API 进行核心业务开发,即可实现快速上线和迭代,同时这一能力,同开发者已经使用的云服务相互兼容,并不互斥。
也就是说,只要把数据导入小程序自带的后台,就能通过小程序平台的 API 访问到这些数据,以前了解过第三方的 LeanCloud云 和 Bomb 云,没想到小程序现在集成了这些功能,不得不佩服一下腾讯。
也就是,接下来的后台的工作是主要是导入数据,查询小程序后台可知,后台支持导入 json 或者 csv 格式的数据。于是我就写了个脚本,把数据从本地数据库导出到 json 文件中:
import psycopg2import json# 连接 pgsql 数据库,为保证隐私,密码已隐藏conn = psycopg2.connect(database="gaokao", user="postgres", password="*******", host="127.0.0.1", port="5432")cur = conn.cursor()cur.execute('select stu_loc,year,stu_wl,pc,control from province')result = []query_res = cur.fetchall()for i in query_res: item = {} item['stu_loc'] = i[0] item['year'] = i[1] item['wl'] = i[2] item['pc'] = i[3] item['score'] = i[4] result.append(item)# indent=2 控制 json 格式的缩进# ensure_ascii 控制中文的正常显示with open("province.json", 'w', encoding="utf-8") as f: f.write(json.dumps(result, indent=2, ensure_ascii=False)) 这里还有有个坑需要说明一下,小程序后台要求的 json 格式和我们平常意义上的 json 格式还有点区别,首先,json 的所有内容不能被 [ 和 ] 包括起来,而且每个被 {} 所包括得数据项之间不能有逗号。
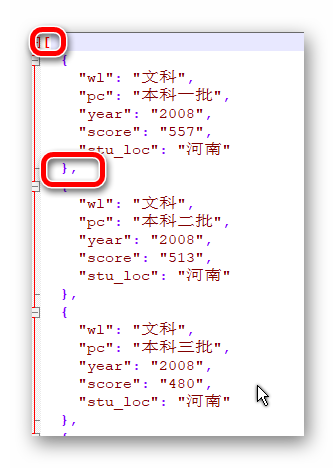
选用 notepad++ 打开原来的 json 文件,使用替换功能就能解决,把 [ 和 ] 替换成空格,把 },替换成 } 即可。
修改之后,在小程序后台通过导入该 json 文件,后台搭建就基本完成了。
小程序端编写
关于小程序端的编写,我主要谈谈两点经验,第一是页面的编写,比如下面这个界面。
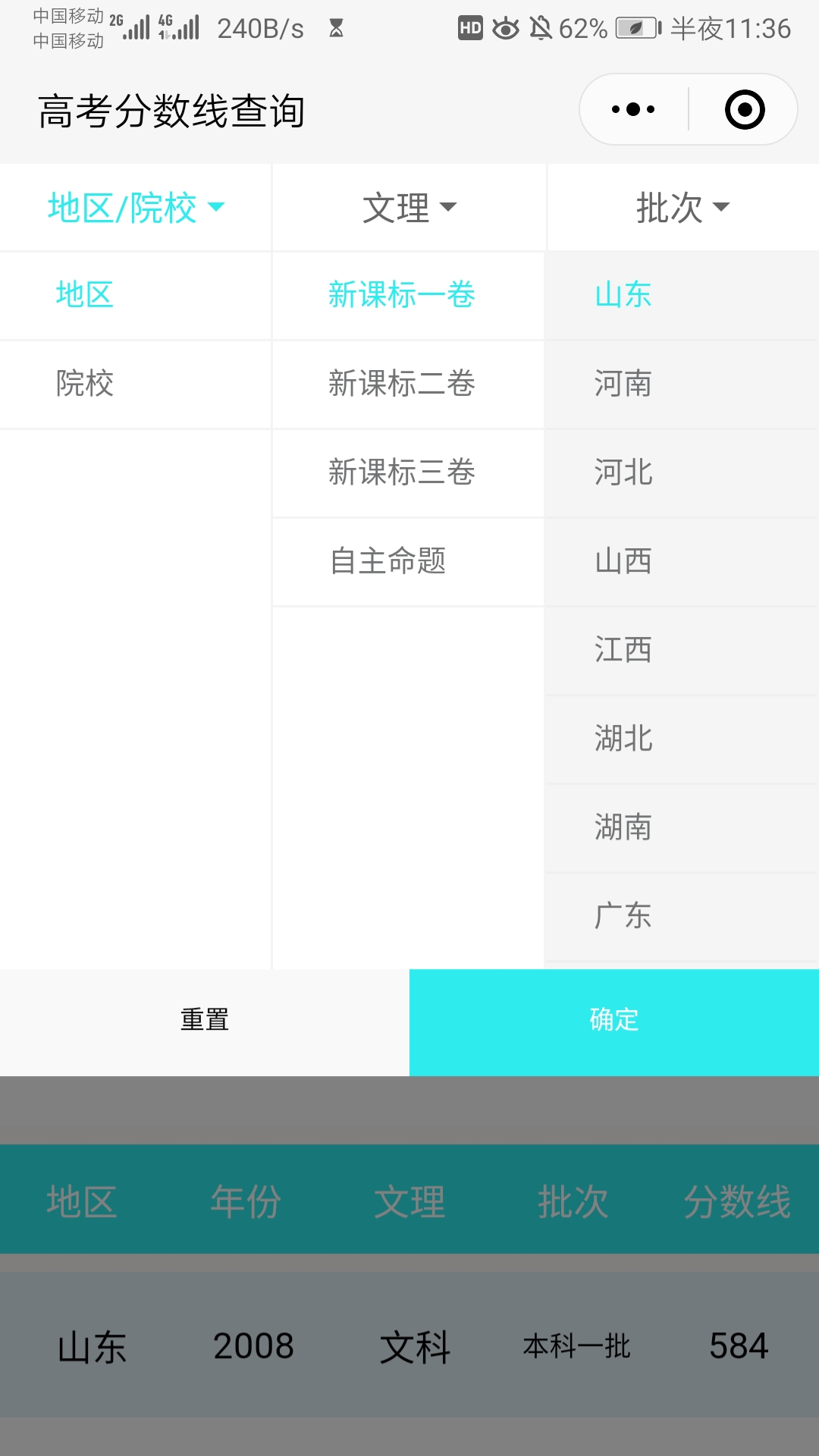
最开始想实现这样的效果,完全没有思路,最后在从自定义模态弹窗那得到了思路,一开始地区院校这个下拉框对应的布局是隐藏的,在 wxml 文件中通过 hidden=true 控制,一点击 地区/院校 下拉框,就把 hidden 置为 false,如果开始有其他下拉框对应的布局的 hidden 属性是 false 的话,同时要把这些布局的 hidden 属性置为 true 来隐藏其他布局,当然,这里的 true or false 需要在 js 里通过 setData() 动态修改,把修改后的数据从数据层渲染到视图层。
第二是关于小程序云开发的原生 Bug,查询后台时一次只能最多查询到 20 条数据,要实现一次得到所有匹配的结果,需要解决两个问题,第一个问题很自然而然就能想到,第一次查到 20 条数据后,第二次跳过前 20 条再取 20 条,第三次跳过前 40 条再取 20 条,以此类推;还有一个更为致命的问题,查询后台的 API 获取结果的回调函数的 异步 的,也就是说,为了保证获得完整数据,第二次查询需要写在第一次查询的回调里,第三次查询需要写在第二次查询的回调里,而且你还不能显式地知道要查询多少次,需要写多少层这样的嵌套,以及烦人的同名变量覆盖问题,这就是所谓的 异步地狱。为了解决这个问题,需要我们编写代码把这个异步方法转成同步的,具体做法是:
先在所要添加功能的js页面中导入 runtime.js 文件,同时把runtime.js文件放入相应文件夹
; const regeneratorRuntime = require("../runtime");runtime.js 下载地址:
同时模仿下例代码完成业务逻辑:
// 查询可能较慢,最好加入加载动画wx.showLoading({ title: '加载中', }) const countResult = await db.collection('province').where({ stu_loc: name, pc: pici, }).count() const total = countResult.total //计算需分几次取 const batchTimes = Math.ceil(total / MAX_LIMIT) // 承载所有读操作的 promise 的数组 //初次循环获取云端数据库的分次数的promise数组 for (let i = 0; i < batchTimes; i++) { const promise = await db.collection('province').where({ stu_loc: name, pc: pici, }).skip(i * MAX_LIMIT).limit(MAX_LIMIT).get() //二次循环根据获取的promise数组的数据长度获取全部数据push到newResult数组中 for (let j = 0; j < promise.data.length; j++) { var item = {}; item.code = i * MAX_LIMIT + j; item.name = promise.data[j].stu_loc; item.year = promise.data[j].year; item.wl = promise.data[j].wl; item.pc = promise.data[j].pc; item.score = promise.data[j].score; console.table(promise.data) newResult.push(item) } } if (newResult.length != 0) { that.setData({ hasdataFlag: true, resultData: newResult }) } else { that.setData({ hasdataFlag: false, resultData: newResult }) } // 隐藏加载动画 wx.hideLoading() 以上就是我本次开发的一些心得体会,欢迎批评指正。
课程完整源码
联系我们
更多云开发使用技巧及 Serverless 行业动态,扫码关注我们~
